本文共 12367 字,大约阅读时间需要 41 分钟。
谨以此文献给李林锋新生的爱女。
李林锋此后还将在 InfoQ 上开设 Netty 专题持续出稿,感兴趣的同学可以持续关注。
1. 背景
1.1 直播平台内存泄漏问题
某直播平台,一些网红的直播间在业务高峰期,会有10W+的粉丝接入,如果瞬间发生大量客户端连接掉线、或者一些客户端网络比较慢,发现基于Netty构建的服务端内存会飙升,发生内存泄漏(OOM),导致直播卡顿、或者客户端接收不到服务端推送的消息,用户体验受到很大影响。
1.2 问题分析
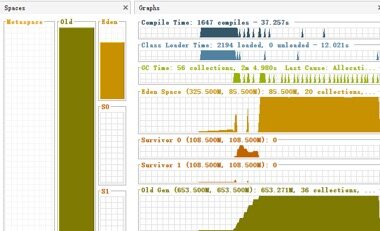
首先对GC数据进行分析,发现老年代已满,发生多次Full GC,耗时达3分多,系统已经无法正常运行(示例):
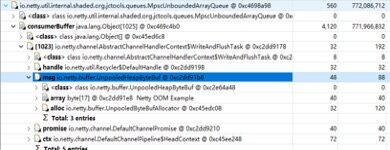
Dump内存堆栈进行分析,发现大量的发送任务堆积,导致内存溢出(示例):
通过以上分析可以看出,在直播高峰期,服务端向上万客户端推送消息时,发生了发送队列积压,引起内存泄漏,最终导致服务端频繁GC,无法正常处理业务。
1.3 解决策略
服务端在进行消息发送的时候做保护,具体策略如下:
根据可接入的最大用户数做客户端并发接入数流控,需要根据内存、CPU处理能力,以及性能测试结果做综合评估。
设置消息发送的高低水位,针对消息的平均大小、客户端并发接入数、JVM内存大小进行计算,得出一个合理的高水位取值。服务端在推送消息时,对Channel的状态进行判断,如果达到高水位之后,Channel的状态会被Netty置为不可写,此时服务端不要继续发送消息,防止发送队列积压。
服务端基于上述策略优化了代码,内存泄漏问题得到解决。
1.4.总结
尽管Netty框架本身做了大量的可靠性设计,但是对于具体的业务场景,仍然需要用户做针对特定领域和场景的可靠性设计,这样才能提升应用的可靠性。
除了消息发送积压导致的内存泄漏,Netty还有其它常见的一些内存泄漏点,本文将针对这些可能导致内存泄漏的功能点进行分析和总结。
2. 消息收发防内存泄漏策略
2.1.消息接收
2.1.1 消息读取
Netty的消息读取并不存在消息队列,但是如果消息解码策略不当,则可能会发生内存泄漏,主要有如下几点:
1.畸形码流攻击:如果客户端按照协议规范,将消息长度值故意伪造的非常大,可能会导致接收方内存溢出。
2.代码BUG:错误的将消息长度字段设置或者编码成一个非常大的值,可能会导致对方内存溢出。
3.高并发场景:单个消息长度比较大,例如几十M的小视频,同时并发接入的客户端过多,会导致所有Channel持有的消息接收ByteBuf内存总和达到上限,发生OOM。
避免内存泄漏的策略如下:
- 无论采用哪种解码器实现,都对消息的最大长度做限制,当超过限制之后,抛出解码失败异常,用户可以选择忽略当前已经读取的消息,或者直接关闭链接。
以Netty的DelimiterBasedFrameDecoder代码为例,创建DelimiterBasedFrameDecoder对象实例时,指定一个比较合理的消息最大长度限制,防止内存溢出:
/** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param stripDelimiter whether the decoded frame should strip out the * delimiter or not * @param delimiter the delimiter */public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, ByteBuf delimiter) { this(maxFrameLength, stripDelimiter, true, delimiter);} - 需要根据单个Netty服务端可以支持的最大客户端并发连接数、消息的最大长度限制以及当前JVM配置的最大内存进行计算,并结合业务场景,合理设置maxFrameLength的取值。
2.1.2 ChannelHandler的并发执行
Netty的ChannelHandler支持串行和异步并发执行两种策略,在将ChannelHandler加入到ChannelPipeline时,如果指定了EventExecutorGroup,则ChannelHandler将由EventExecutorGroup中的EventExecutor异步执行。这样的好处是可以实现Netty I/O线程与业务ChannelHandler逻辑执行的分离,防止ChannelHandler中耗时业务逻辑的执行阻塞I/O线程。
ChannelHandler异步执行的流程如下所示:
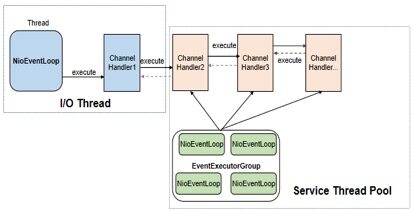
如果业务ChannelHandler中执行的业务逻辑耗时较长,消息的读取速度又比较快,很容易发生消息在EventExecutor中积压的问题,如果创建EventExecutor时没有通过io.netty.eventexecutor.maxPendingTasks参数指定积压的最大消息个数,则默认取值为0x7fffffff,长时间的积压将导致内存溢出,相关代码如下所示(异步执行ChannelHandler,将消息封装成Task加入到taskQueue中):
public void execute(Runnable task) { if (task == null) { throw new NullPointerException(\u0026quot;task\u0026quot;); } boolean inEventLoop = inEventLoop(); if (inEventLoop) { addTask(task); } else { startThread(); addTask(task); if (isShutdown() \u0026amp;\u0026amp; removeTask(task)) { reject(); } } 解决对策:对EventExecutor中任务队列的容量做限制,可以通过io.netty.eventexecutor.maxPendingTasks参数做全局设置,也可以通过构造方法传参设置。结合EventExecutorGroup中EventExecutor的个数来计算taskQueue的个数,根据taskQueue * N * 任务队列平均大小 * maxPendingTasks \u0026lt; 系数K(0 \u0026lt; K \u0026lt; 1)* 总内存的公式来进行计算和评估。
2.2.消息发送
2.2.1 如何防止发送队列积压
为了防止高并发场景下,由于对方处理慢导致自身消息积压,除了服务端做流控之外,客户端也需要做并发保护,防止自身发生消息积压。
利用Netty提供的高低水位机制,可以实现客户端更精准的流控,它的工作原理如下:

当发送队列待发送的字节数组达到高水位上限时,对应的Channel就变为不可写状态。由于高水位并不影响业务线程调用write方法并把消息加入到待发送队列中,因此,必须要在消息发送时对Channel的状态进行判断:当到达高水位时,Channel的状态被设置为不可写,通过对Channel的可写状态进行判断来决定是否发送消息。
在消息发送时设置高低水位并对Channel状态进行判断,相关代码示例如下:
public void channelActive(final ChannelHandlerContext ctx) { **ctx.channel().config().setWriteBufferHighWaterMark(10 \\* 1024 * 1024);** loadRunner = new Runnable() { @Override public void run() { try { TimeUnit.SECONDS.sleep(30); } catch (InterruptedException e) { e.printStackTrace(); } ByteBuf msg = null; while (true) { **if (ctx.channel().isWritable()) {** msg = Unpooled.wrappedBuffer(\u0026quot;Netty OOM Example\u0026quot;.getBytes()); ctx.writeAndFlush(msg); } else { LOG.warning(\u0026quot;The write queue is busy : \u0026quot; + ctx.channel().unsafe().outboundBuffer().nioBufferSize()); } } } }; new Thread(loadRunner, \u0026quot;LoadRunner-Thread\u0026quot;).start(); } 对上述代码做验证,客户端代码中打印队列积压相关日志,说明基于高水位的流控机制生效,日志如下:
警告: The write queue is busy : 17
通过内存监控,发现内存占用平稳:
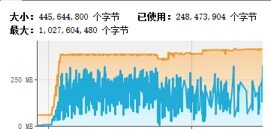
在实际项目中,根据业务QPS规划、客户端处理性能、网络带宽、链路数、消息平均码流大小等综合因素计算并设置高水位(WriteBufferHighWaterMark)阈值,利用高水位做消息发送速率的流控,既可以保护自身,同时又能减轻服务端的压力,防止服务端被压挂。
2.2.2 其它可能导致发送队列积压的因素
需要指出的是,并非只有高并发场景才会触发消息积压,在一些异常场景下,尽管系统流量不大,但仍然可能会导致消息积压,可能的场景包括:
网络瓶颈,发送速率超过网络链接处理能力时,会导致发送队列积压。
对端读取速度小于己方发送速度,导致自身TCP发送缓冲区满,频繁发生write 0字节时,待发送消息会在Netty发送队列排队。
当出现大量排队时,很容易导致Netty的直接内存泄漏,示例如下:
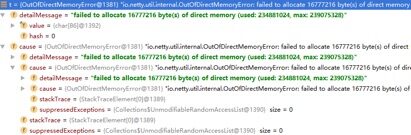
我们在设计系统时,需要根据业务的场景、所处的网络环境等因素进行综合设计,为潜在的各种故障做容错和保护,防止因为外部因素导致自身发生内存泄漏。
3. ByteBuf的申请和释放策略
3.1 ByteBuf申请和释放的理解误区
有一种说法认为Netty框架分配的ByteBuf框架会自动释放,业务不需要释放;业务创建的ByteBuf则需要自己释放,Netty框架不会释放。
事实上,这种观点是错误的,即便ByteBuf是Netty创建的,如果使用不当仍然会发生内存泄漏。在实际项目中如何更好的管理ByteBuf,下面我们分四种场景进行说明。
3.2 ByteBuf的释放策略
3.2.1 基于内存池的请求ByteBuf
这类ByteBuf主要包括PooledDirectByteBuf和PooledHeapByteBuf,它由Netty的NioEventLoop线程在处理Channel的读操作时分配,需要在业务ChannelInboundHandler处理完请求消息之后释放(通常是解码之后),它的释放有2种策略:
- 策略1:业务ChannelInboundHandler继承自SimpleChannelInboundHandler,实现它的抽象方法channelRead0(ChannelHandlerContext ctx, I msg),ByteBuf的释放业务不用关心,由SimpleChannelInboundHandler负责释放,相关代码如下所示(SimpleChannelInboundHandler):
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { boolean release = true; try { if (acceptInboundMessage(msg)) { I imsg = (I) msg; channelRead0(ctx, imsg); } else { release = false; ctx.fireChannelRead(msg); } } finally { **if (autoRelease \u0026amp;\u0026amp; release) {** **ReferenceCountUtil.release(msg);** **}** } } 如果当前业务ChannelInboundHandler需要执行,则调用完channelRead0之后执行ReferenceCountUtil.release(msg)释放当前请求消息。如果没有匹配上需要继续执行后续的ChannelInboundHandler,则不释放当前请求消息,调用ctx.fireChannelRead(msg)驱动ChannelPipeline继续执行。
继承自SimpleChannelInboundHandler,即便业务不释放请求ByteBuf对象,依然不会发生内存泄漏,相关示例代码如下所示:
public class RouterServerHandlerV2 **extends SimpleChannelInboundHandler\u0026lt;ByteBuf\u0026gt;** {//代码省略...@Override public void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) { byte [] body = new byte[msg.readableBytes()]; executorService.execute(()-\u0026gt; { //解析请求消息,做路由转发,代码省略... //转发成功,返回响应给客户端 ByteBuf respMsg = allocator.heapBuffer(body.length); respMsg.writeBytes(body);//作为示例,简化处理,将请求返回 ctx.writeAndFlush(respMsg); }); } 对上述代码做性能测试,发现内存占用平稳,无内存泄漏问题,验证了之前的分析结论。
- 策略2:在业务ChannelInboundHandler中调用ctx.fireChannelRead(msg)方法,让请求消息继续向后执行,直到调用到DefaultChannelPipeline的内部类TailContext,由它来负责释放请求消息,代码如下所示(TailContext):
protected void onUnhandledInboundMessage(Object msg) { try { logger.debug( \u0026quot;Discarded inbound message {} that reached at the tail of the pipeline. \u0026quot; + \u0026quot;Please check your pipeline configuration.\u0026quot;, msg); **} finally {** **ReferenceCountUtil.release(msg);** **}** } 3.2.2 基于非内存池的请求ByteBuf
如果业务使用非内存池模式覆盖Netty默认的内存池模式创建请求ByteBuf,例如通过如下代码修改内存申请策略为Unpooled:
//代码省略... .childHandler(new ChannelInitializer\u0026lt;SocketChannel\u0026gt;() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); ch.config().setAllocator(UnpooledByteBufAllocator.DEFAULT); p.addLast(new RouterServerHandler()); } }); } 也需要按照内存池的方式去释放内存。
3.2.3 基于内存池的响应ByteBuf
只要调用了writeAndFlush或者flush方法,在消息发送完成之后都会由Netty框架进行内存释放,业务不需要主动释放内存。
它的工作原理如下:
调用ctx.writeAndFlush(respMsg)方法,当消息发送完成之后,Netty框架会主动帮助应用来释放内存,内存的释放分为两种场景:
- 如果是堆内存(PooledHeapByteBuf),则将HeapByteBuffer转换成DirectByteBuffer,并释放PooledHeapByteBuf到内存池,代码如下(AbstractNioChannel类):
protected final ByteBuf newDirectBuffer(ByteBuf buf) { final int readableBytes = buf.readableBytes(); if (readableBytes == 0) { **ReferenceCountUtil.safeRelease(buf);** return Unpooled.EMPTY_BUFFER; } final ByteBufAllocator alloc = alloc(); if (alloc.isDirectBufferPooled()) { ByteBuf directBuf = alloc.directBuffer(readableBytes); directBuf.writeBytes(buf, buf.readerIndex(), readableBytes); **ReferenceCountUtil.safeRelease(buf);** return directBuf; } } //后续代码省略} 如果消息完整的被写到SocketChannel中,则释放DirectByteBuffer,代码如下(ChannelOutboundBuffer)所示:
public boolean remove() { Entry e = flushedEntry; if (e == null) { clearNioBuffers(); return false; } Object msg = e.msg; ChannelPromise promise = e.promise; int size = e.pendingSize; removeEntry(e); if (!e.cancelled) { **ReferenceCountUtil.safeRelease(msg);** safeSuccess(promise); decrementPendingOutboundBytes(size, false, true); } //后续代码省略} 对Netty源码进行断点调试,验证上述分析:
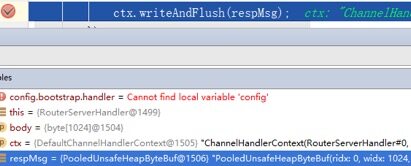
断点1:在响应消息发送处打印断点,获取到PooledUnsafeHeapByteBuf实例ID为1506。
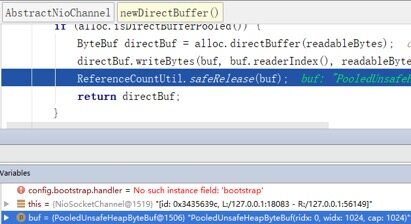
断点2:在HeapByteBuffer转换成DirectByteBuffer处打断点,发现实例ID为1506的PooledUnsafeHeapByteBuf被释放。
断点3:转换之后待发送的响应消息PooledUnsafeDirectByteBuf实例ID为1527。

断点4:响应消息发送完成之后,实例ID为1527的PooledUnsafeDirectByteBuf被释放到内存池。
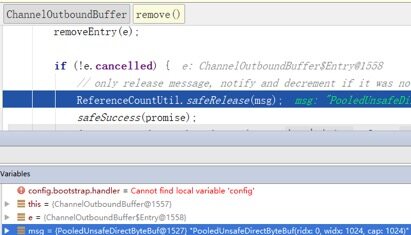
- 如果是DirectByteBuffer,则不需要转换,当消息发送完成之后,由ChannelOutboundBuffer的remove()负责释放。
3.2.4 基于非内存池的响应ByteBuf
无论是基于内存池还是非内存池分配的ByteBuf,如果是堆内存,则将堆内存转换成堆外内存,然后释放HeapByteBuffer,待消息发送完成之后,再释放转换后的DirectByteBuf;如果是DirectByteBuffer,则无需转换,待消息发送完成之后释放。因此对于需要发送的响应ByteBuf,由业务创建,但是不需要业务来释放。
4. Netty服务端高并发保护
4.1 高并发场景下的OOM问题
在RPC调用时,如果客户端并发连接数过多,服务端又没有针对并发连接数的流控机制,一旦服务端处理慢,就很容易发生批量超时和断连重连问题。
以Netty HTTPS服务端为例,典型的业务组网示例如下所示:
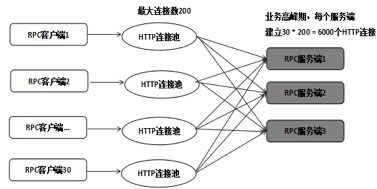
客户端采用HTTP连接池的方式与服务端进行RPC调用,单个客户端连接池上限为200,客户端部署了30个实例,而服务端只部署了3个实例。在业务高峰期,每个服务端需要处理6000个HTTP连接,当服务端时延增大之后,会导致客户端批量超时,超时之后客户端会关闭连接重新发起connect操作,在某个瞬间,几千个HTTPS连接同时发起SSL握手操作,由于服务端此时也处于高负荷运行状态,就会导致部分连接SSL握手失败或者超时,超时之后客户端会继续重连,进一步加重服务端的处理压力,最终导致服务端来不及释放客户端close的连接,引起NioSocketChannel大量积压,最终OOM。
通过客户端的运行日志可以看到一些SSL握手发生了超时,示例如下:
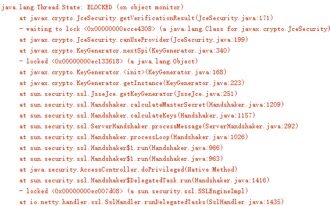
服务端并没有对客户端的连接数做限制,这会导致尽管ESTABLISHED状态的连接数并不会超过6000上限,但是由于一些SSL连接握手失败,再加上积压在服务端的连接并没有及时释放,最终引起了NioSocketChannel的大量积压。
4.2.Netty HTTS并发连接数流控
在服务端增加对客户端并发连接数的控制,原理如下所示:
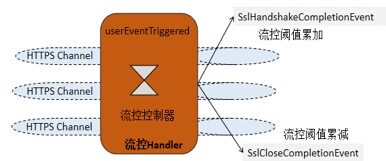
基于Netty的Pipeline机制,可以对SSL握手成功、SSL连接关闭做切面拦截(类似于Spring的AOP机制,但是没采用反射机制,性能更高),通过流控切面接口,对HTTPS连接做计数,根据计数器做流控,服务端的流控算法如下:
获取流控阈值。
从全局上下文中获取当前的并发连接数,与流控阈值对比,如果小于流控阈值,则对当前的计数器做原子自增,允许客户端连接接入。
如果等于或者大于流控阈值,则抛出流控异常给客户端。
SSL连接关闭时,获取上下文中的并发连接数,做原子自减。
在实现服务端流控时,需要注意如下几点:
流控的ChannelHandler声明为@ChannelHandler.Sharable,这样全局创建一个流控实例,就可以在所有的SSL连接中共享。
通过userEventTriggered方法拦截SslHandshakeCompletionEvent和SslCloseCompletionEvent事件,在SSL握手成功和SSL连接关闭时更新流控计数器。
流控并不是单针对ESTABLISHED状态的HTTP连接,而是针对所有状态的连接,因为客户端关闭连接,并不意味着服务端也同时关闭了连接,只有SslCloseCompletionEvent事件触发时,服务端才真正的关闭了NioSocketChannel,GC才会回收连接关联的内存。
流控ChannelHandler会被多个NioEventLoop线程调用,因此对于相关的计数器更新等操作,要保证并发安全性,避免使用全局锁,可以通过原子类等提升性能。
5. 总结
5.1.其它的防内存泄漏措施
5.1.1 NioEventLoop
执行它的execute(Runnable task)以及定时任务相关接口时,如果任务执行耗时过长、任务执行频度过高,可能会导致任务队列积压,进而引起OOM:
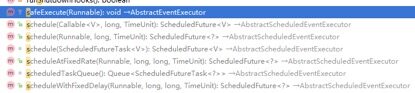
建议业务在使用时,对NioEventLoop队列的积压情况进行采集和告警。
5.1.2 客户端连接池
业务在初始化连接池时,如果采用每个客户端连接对应一个EventLoopGroup实例的方式,即每创建一个客户端连接,就会同时创建一个NioEventLoop线程来处理客户端连接以及后续的网络读写操作,采用的策略是典型的1个TCP连接对应一个NIO线程的模式。当系统的连接数很多、堆内存又不足时,就会发生内存泄漏或者线程创建失败异常。问题示意如下:
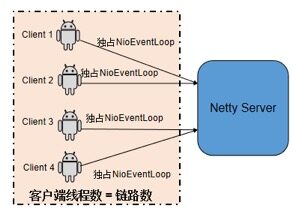
优化策略:客户端创建连接池时,EventLoopGroup可以重用,优化之后的连接池线程模型如下所示:
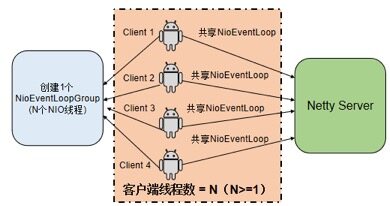
5.2 内存泄漏问题定位
5.2.1 堆内存泄漏
通过jmap -dump:format=b,file=xx pid命令Dump内存堆栈,然后使用MemoryAnalyzer工具对内存占用进行分析,查找内存泄漏点,然后结合代码进行分析,定位内存泄漏的具体原因,示例如下所示:
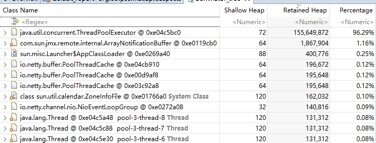
5.2.2 堆外内存泄漏
建议策略如下:
排查下业务代码,看使用堆外内存的地方是否存在忘记释放问题。
如果使用到了Netty的TLS/SSL/openssl,建议到Netty社区查下BUG列表,看是否是Netty老版本已知的BUG,此类BUG通过升级Netty版本可以解决。
如果上述两个步骤排查没有结果,则可以通过google-perftools工具协助进行堆外内存分析。
6. 作者简介
李林锋,10年Java NIO、平台中间件设计和开发经验,精通Netty、Mina、分布式服务框架、API Gateway、PaaS等,《Netty进阶之路》、《分布式服务框架原理与实践》作者。目前在华为终端应用市场负责业务微服务化、云化、全球化等相关设计和开发工作。
联系方式:新浪微博 Nettying 微信:Nettying
Email:neu_lilinfeng@sina.com
转载地址:http://wicix.baihongyu.com/